
Ray Kurzweil believes in the singularity. He’s arranged to have his body cryogenically frozen. He’s a pioneer in optical character recognition, speech recognition, and speech-to-text technology. He’s been hobnobbing with Silicon Valley tech elites since forever. And he loves and has deep knowledge about music and sound.

In the early 80s, he had a conversation with Stevie Wonder that changed the sound of music. Wonder was bemoaning the lack of musicality in electronic keyboard instruments, and Kurzweil had some ideas. Soon enough, they co-founded Kurzweil Music Systems, which built astonishingly life-like emulations of the piano and other acoustic instruments. If you wanted the best-sounding digital piano money could buy in the 80s, it was a Kurzweil.
Recent advances in AI got me thinking about Kurzweil’s 1999 book, The Age of Spiritual Machines. I started wondering how it’s held up over time, especially with regard to predictions that are relevant to the current AI/LLM/machine learning landscape and/or the current state of music and sound technologies. So I dusted off my old copy and dove back in to find out.
As a refresher, or an introduction for anyone who missed this book, The Age of Spiritual Machines was written in 1999 to predict the path toward the singularity, “when computers exceed human intelligence.” The first two parts are fairly typical of a non-fiction book — explorations of concepts and ideas through Kurzweil’s lens. Part three is where the predictions start.
Kurzweil makes three sets of ten-year predictions (2009, 2019, and 2029), then skips to 2099, where there’s no longer a distinction between humans and computers. By 2099, Kurzweil thought, we’ll have reached the singularity.
Like so many futurists, Kurzweil was optimistic in his timeline. Here in 2023, we’ve moved slower than he expected us to. In a fantastic post on the forum LessWrong, user Stuart_Amstrong undertook a project to enlist the community to assess of the accuracy of Kurzweil’s predictions for 2009 and 2019. Here’s what he found:

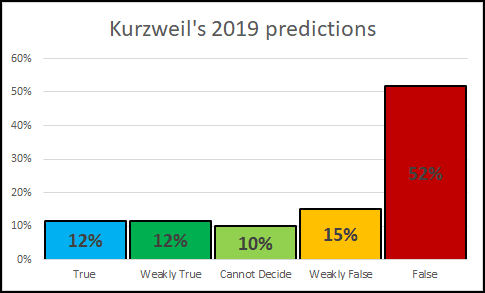
I would suggest, however, that the timeline is more flawed than the predictions themselves. With a few exceptions, our 2023 looks exceptionally like Kurzweil’s 2009. So let’s look at some specific predictions that are relevant to where we sit today, in 2023. Since 2019 predictions were only 12% true as of 2020, let’s look at 2009, which holds the most currently-relevant predictions for music and sound.
Prediction 1: Sound in Space
Sound producing speakers are being replaced with very small chip-based devices that can place high resolution sound anywhere in three dimensional space. This technology is based on creating audible frequency sounds from the spectrum created by the interaction of very high frequency tones. As a result, very small computers can create very robust three-dimensional sound.
The Age of Spiritual Machines pp. 190-91
Fortunately, we have a local spatial audio expert at PatternSonix. I asked Greg to comment on the state of this prediction in 2023:
It exists, although not in the ways Kurzweil predicted. He was talking about devices that could generate and de-code ultrasonic sound, thereby using ultrasonic (i.e. non-audible) frequencies to locate a sound in 3D space. While ultrasonic sound is used in industry (marketing, grocery stores, advertising, military/defense, etc.), it’s not in standard consumer tech, because decoding ultrasonic frequencies to audible frequencies and spatializing them is quite a challenge. That said, there’s work being done to make this prediction come true.
Spatial sound as a concept, though, has taken great strides into consumer tech, especially w/ Dolby Atmos & Apple’s spatial audio, but there are still challenges for widespread adoption. For spatial audio to be truly high-fidelity and convincing (in my opinion), you have to have a multiple speaker set-up, which is rare. In home Dolby systems, the sound is bounced off surfaces in an attempt to create 3D sound, which is much less successful. And the binaural reductions created for headphones, like in Apple’s spatial audio, can sound great, but still don’t really capture the sense of a true 3D space.
The real commercial promise of these technologies is, of course, in virtual, augmented, and mixed reality uses. If the Metaverse takes off, we’ll need to see continued investment in spatial sound, as people will need and expect it to create meaningful virtual experiences.
Dr. Greg Wilder
Prediction 2: The Democratization of Music
Human musicians routinely jam with cybernetic musicians. The creation of music has become available to persons who are not musicians. Creating music does not necessarily require the fine motor coordination of using traditional controllers. Cybernetic music creation systems allow people who appreciate music but who are not knowledgeable about music theory and practice to create music in collaboration with their automatic composition software. Interactive brain-generated music, which creates a resonance between the user’s brain waves and the music being listened to, is another popular genre.
Musicians commonly use electronic controllers that emulate the playing style of the old acoustic instruments (for example, piano, guitar, violin, drums), but there is a surge of interest in the new “air” controllers in which you create music by moving your hands, feet, mouth, and other body parts. Other music controllers involve interacting with specially designed devices.
The Age of Spiritual Machines, p. 196
As I mentioned up top, Kurzweil has a special interest in and knowledge of musical instrument design, so I find these predictions especially intriguing. He certainly got the spirit of this prediction right, although some of the details that are wrong are very wrong.
Algorithmically-generated real-time music is the closest thing we have to his “cybernetic musicians,” other than some quirky but awesome attempts at robot bands. Algorithmically-generated pitches and rhythms are in wide use on iPads, in Ableton/Bitwig/FL Studio-like DAWs, and in modular synthesizer systems. These systems divide into three basic categories:
- Rule-based systems that follow simplistic conceptions of music theory, putting guardrails on the musician, enforcing things like commonly-used chords, notes within scales, and Euclidean-type symmetrical rhythms
- Random systems that let the user set some ground rules, then produce random pitches and rhythms within that set of options
- Machine learning-based systems that allow the musician to specify things like genre, tempo, and use case

Despite following some basic “rules” that music has evolved to include, these systems aren’t exactly making human-like music. In fact, I’d say humans are adapting themselves to become accustomed to the algorithms’ habits and capabilities, rather than the other way around. These systems don’t require or encourage the intricacies of the great instrumentalist, who spends a lifetime learning to combine incredible dexterity and fine motor skills with the flow state necessary to play an instrument at the highest level. We can each decide whether we want to bemoan that loss or not, but the state of algorithmic music generation doesn’t include a convincing imitation of the musicianship of a seasoned performer. So if Kurzweil hoped that people would be able to jam with, say, John Bonham on cybernetic drums, he must be disappointed in the state of things today.
That said, he was 100% right about technologies opening up the world of creative music-making to people who don’t have deep knowledge of music theory and practice, as well as about new controllers.

The “air” controllers he mentioned were probably an allusion to something that existed in the late 90s when he was writing the book: the Alesis Air FX. That product was, at the time, a super futuristic effects processor that allowed you to control on-board effects via waving your hand around over an infrared light. So, like many of his predictions, he was extrapolating based on something currently-available he thought was future-looking.
While motion controllers have certainly stayed around (see the revival of the Leap Motion controller), they’re not a primary way most musicians accomplish sound creation. It seems that the simplification/algorithmification of pitch and rhythm generation, coupled with the humble knob, has won that race, at least for now.
Prediction 3: Portrait of the Machine as Artist
Predictions get ever less specific as Kurzweil moves through the 21st century. For example, in the 2029 section, which is the last year he treats in any detail (and which is NOT far away, ahem), he just says:
Cybernetic artists in all of the arts—musical, visual, literary, virtual experience, and all others— no longer need to associate themselves with humans or organizations that include humans. Many of the leading artists are machines.
Again, there are pockets where this prediction rings a bit true. Young people in Asia have been going crazy for virtual celebrities for years at this point, including Japanese superstar Hatsune Miku, who began as a model among many in a vocal synthesizer and grew to full-fledged virtual performer, with a 3D presence on stage and collabs with the likes of Lady Gaga and Pharrell Williams.
Of course, Miku isn’t an AI, but is based a few different clever programming layers, as well as a lot of good, old-fashioned human elbow grease. The birth of Miku happened in Yamaha’s Vocaloid synthesizer, which is a combination of spectral modeling and source filter synthesis that essentially takes a library of recordings of the human voices and molds it into what you tell it to say.
Bonus Prediction: Machines of Loving Grace
Even if we limit our discussion to computers that are not directly derived from a particular human brain, they will increasingly appear to have their own personalities, evidencing reactions that we can only label as emotions and articulating their own goals and purposes. They will appear to have their own free will. They will claim to have spiritual experiences. And people — those having carbon-based neurons or otherwise — will believe them.
The Age of Spiritual Machines, p. 6
This is not a prediction for a specific moment, but the overarching prediction of the entire book: that as computers become increasingly powerful and sophisticated, they will not only mimic human intelligence but also exhibit spiritual and emotional qualities.

Leaving out the bits about transferring a singular human consciousness into a machine, this is already becoming prescient. While ChatGPT’s guardrails keep it from claiming that it has a soul (and almost everyone is almost totally sure it can’t possibly have one), there are plenty of virtual romance chatbots out there who are are happy to pretend to be human, all too human.

The most successful, natural-sounding of these systems use state-of-the-art, deep-learning-based neural TTS (text-to-speech) systems to get close to their human customers. Like all sound-based AI, though, these voices could be improved by becoming adaptive to their conversation partners. The cadence sounds fairly natural, especially compared to TTS engines from ten years ago, but it doesn’t specifically speak in ways that its conversation partner likes and expects. Before we can truly fall in love with them, machines will need to be able to use all the tricks we do when we talk with each other. If this topic interests you, check out our article about patterns in speech.
So that does it for Kurzweil’s sound & music predictions! It’s been a fun romp through an old favorite book — and a book that stands up as fascinating and forward-reaching, if not for its accuracy.